What is Natural Language Processing (NLP)?
Natural Language Processing (NLP) is a branch of Artificial Intelligence (AI) that deals with the interaction between human language and computers. It involves the use of algorithms and computational techniques to process and analyze human language data, such as text and speech.
NLP is used to enable machines to understand, interpret, and generate human language in a way that is similar to the way humans do. It involves a range of techniques including text analysis, information extraction, machine translation, sentiment analysis, speech recognition, and language generation.

NLP is used in a wide range of applications, such as chatbots, virtual assistants, search engines, language translation, and speech recognition software. It has become increasingly important as more data is generated in natural language format, and as businesses and organizations seek to better understand and leverage this data.
History of Natural Language Processing
The history of Natural Language Processing (NLP) dates back to the 1950s, when the development of electronic computers led to the possibility of automating language processing tasks.
The earliest work in NLP involved the development of simple algorithms for language processing, such as the creation of keyword indexes and concordances for texts. In the 1960s and 1970s, researchers began to experiment with more complex techniques for language processing, such as syntax analysis and semantic processing.
One of the earliest breakthroughs in NLP came in the 1950s, when Alan Turing proposed a test to determine whether a machine could exhibit intelligent behavior equivalent to, or indistinguishable from, that of a human. This test, known as the Turing Test, has since become a milestone in the field of AI and NLP.
In the 1960s and 1970s, researchers at universities and research institutions around the world began to develop NLP systems capable of performing tasks such as language translation, speech recognition, and text summarization. One notable example from this time period is the SHRDLU system, developed by Terry Winograd at MIT, which was capable of understanding and responding to natural language commands in a limited domain.
The 1980s and 1990s saw the development of statistical methods for language processing, such as Hidden Markov Models (HMMs) and probabilistic context-free grammars (PCFGs). These techniques allowed for more accurate and robust language processing, and led to the development of commercial NLP applications such as speech recognition systems and machine translation tools.
In recent years, advances in machine learning and deep learning have led to significant progress in NLP, with systems capable of performing tasks such as sentiment analysis, question answering, and language generation. Today, NLP is a rapidly growing field with applications in a wide range of industries, from healthcare and finance to entertainment and social media.
Two categories of NLP Tasks
The two broad categories of NLP tasks are:
1. NLP Analysis Tasks: These tasks involve analyzing and understanding the structure, meaning, and context of natural language text. Examples include part-of-speech tagging, named entity recognition, sentiment analysis, and text classification.
2. NLP Generation Tasks: These tasks involve generating natural language text, either from scratch or based on input data. Examples include text generation, machine translation, summarization, and dialogue generation.

NLP Analysis Tasks:
Part-of-speech (POS) tagging: Part-of-speech (POS) tagging is an NLP analysis task that involves labeling each word in a sentence with its corresponding part of speech, such as noun, verb, adjective, adverb, etc. POS tagging is important because the same word can have different meanings and functions depending on its part of speech in a sentence.
POS tagging is typically done using statistical models or rule-based systems. Statistical models use machine learning algorithms to learn patterns from large amounts of labeled data, while rule-based systems rely on hand-crafted rules and patterns.
The output of POS tagging is a sequence of word-tag pairs, where each word is labeled with its corresponding part of speech tag. For example, in the sentence “The cat sat on the mat”, the word “cat” would be tagged as a noun (NN), “sat” as a verb (VBD), “on” as a preposition (IN), and so on.
POS tagging is a fundamental task in many downstream NLP applications, such as information extraction, sentiment analysis, and machine translation, among others.
Named entity recognition (NER): Named entity recognition (NER) is an NLP analysis task that involves identifying and classifying named entities in a text, such as people, organizations, locations, and other types of named entities. The goal of NER is to locate and classify these entities in text and label them with their corresponding entity types.
NER is important because named entities often carry important information and can be used to extract structured data from unstructured text data. For example, in a news article, named entities can include the names of people, places, and organizations mentioned in the article.
NER can be done using machine learning models or rule-based systems. Machine learning models use annotated training data to learn patterns and relationships between words and entity types, while rule-based systems rely on hand-crafted rules and patterns.
The output of NER is a set of entities with their corresponding entity types, such as person, organization, or location. For example, in the sentence “John Smith is the CEO of ABC Corporation”, the named entity “John Smith” would be labeled as a person, and “ABC Corporation” would be labeled as an organization.
NER is a crucial task in many NLP applications, such as information extraction, question answering, and text classification.
Sentiment analysis: Sentiment analysis is an NLP analysis task that involves determining the emotional tone of a text, typically positive, negative, or neutral. The goal of sentiment analysis is to automatically extract and quantify subjective information from text data.
Sentiment analysis is important because it can help organizations understand the opinions, attitudes, and emotions of their customers or users towards their products, services, or brands. It can also be used to monitor social media and news feeds for public opinion on a particular topic or event.
Sentiment analysis can be done using different approaches, including rule-based systems, machine learning models, and deep learning models. Rule-based systems rely on hand-crafted rules and patterns to identify sentiment words and phrases and assign them a polarity score. Machine learning models use annotated training data to learn patterns and relationships between words and their sentiment labels. Deep learning models, such as neural networks, can learn complex representations of text data and perform sentiment analysis with high accuracy.
The output of sentiment analysis is a polarity score or label, indicating whether the text is positive, negative, or neutral. Some sentiment analysis systems may also provide more detailed sentiment labels, such as “very positive” or “slightly negative”.
Sentiment analysis is widely used in many applications, such as customer feedback analysis, brand monitoring, market research, and social media analytics, among others.
Text classification: Text classification is an NLP analysis task that involves categorizing text documents into predefined categories or topics based on their content. The goal of text classification is to automatically classify text data and assign it to the appropriate category.
Text classification is important because it can help organizations automate content moderation, filter spam emails, and organize large amounts of unstructured text data. It can also be used in applications such as sentiment analysis, news categorization, and topic modeling.
Text classification can be done using different approaches, including rule-based systems, machine learning models, and deep learning models. Rule-based systems rely on hand-crafted rules and patterns to classify text data based on keywords, phrases, or other features. Machine learning models use annotated training data to learn patterns and relationships between words and their corresponding categories. Deep learning models, such as neural networks, can learn complex representations of text data and perform text classification with high accuracy.
The output of text classification is a category label, indicating the category or topic that the text belongs to. For example, in a news article dataset, the text may be classified into categories such as sports, politics, business, or entertainment.
Text classification is widely used in many applications, such as email spam filtering, content moderation, product categorization, and sentiment analysis, among others.
Dependency parsing: Dependency parsing is an NLP analysis task that involves analyzing the grammatical structure of a sentence and identifying the relationships between words based on their syntactic dependencies. The goal of dependency parsing is to create a tree-like structure that represents the syntactic structure of the sentence.
In a dependency tree, each word in the sentence is represented as a node, and the relationships between words are represented as directed edges. The head of each dependency relation is usually the most important or prominent word in the relation, while the dependent is the word that is modifying or dependent on the head.
Dependency parsing is important because it can help understand the meaning and structure of sentences, and it is often used as a pre-processing step in many NLP applications, such as machine translation, text summarization, and question answering.
Dependency parsing can be done using different approaches, including rule-based systems, statistical models, and neural networks. Statistical models, such as the dependency parsing models based on the transition-based or graph-based algorithms, use annotated training data to learn the most probable dependency tree structures.
The output of dependency parsing is a dependency tree that represents the syntactic structure of the sentence. Each node in the tree corresponds to a word in the sentence, and each edge represents a syntactic dependency between words.
Dependency parsing is a fundamental task in many NLP applications, such as information extraction, machine translation, and natural language understanding.
Topic modeling: Topic modeling is an NLP analysis task that involves identifying topics or themes that occur in a collection of documents or text data. The goal of topic modeling is to automatically discover the underlying topics or themes in a large corpus of text data and represent them as a set of latent variables.
Topic modeling is important because it can help understand the main themes or topics that are discussed in a large corpus of text data and extract insights from it. It can be used in applications such as information retrieval, recommendation systems, and content analysis.
Topic modeling can be done using different approaches, including probabilistic models, matrix factorization methods, and deep learning models. One of the most popular probabilistic models for topic modeling is Latent Dirichlet Allocation (LDA), which represents topics as probability distributions over words and documents as mixtures of topics.
The output of topic modeling is a set of topics, each represented as a probability distribution over words. The most probable words in each topic can be used to describe the main theme or topic represented by the topic.
Topic modeling is widely used in many applications, such as text classification, content analysis, and recommendation systems, among others. It is a powerful tool for exploring large text datasets and uncovering hidden patterns and relationships.
Information extraction: Information extraction is an NLP task that involves automatically extracting structured information from unstructured or semi-structured text data. The goal of information extraction is to identify and extract relevant information from text data and represent it in a structured format, such as a database or a knowledge graph.
Information extraction is important because it can help automate data entry and information retrieval from large text datasets. It can be used in applications such as text mining, content analysis, and business intelligence.
Information extraction can be done using different approaches, including rule-based systems, pattern matching, and machine learning models. Rule-based systems rely on hand-crafted rules and patterns to identify and extract relevant information from text data. Pattern matching involves searching for specific patterns or sequences of words in text data that correspond to the desired information. Machine learning models use annotated training data to learn patterns and relationships between words and their corresponding entities.
The output of information extraction is structured data, such as a database or a knowledge graph, that represents the extracted information in a structured format. For example, in a news article dataset, information extraction may involve extracting the names of the people mentioned in each article, the organizations they are affiliated with, and the relationships between them.
Information extraction is widely used in many applications, such as named entity recognition, relationship extraction, and event extraction, among others. It is a powerful tool for automating data entry and extracting structured information from large text datasets.
NLP Generation Tasks:
Text generation: Text generation is an NLP task that involves generating natural language text from a machine learning model. The goal of text generation is to create coherent and meaningful text that can mimic the writing style of a human author.
Text generation can be done using different approaches, including rule-based systems, template-based systems, and machine learning models. Machine learning models are the most popular approach for text generation, and they can be further divided into two categories: language models and generative models.
Language models are machine learning models that predict the probability of a word given its context. They can be used for tasks such as next-word prediction and text completion.
Generative models, such as the popular GPT (Generative Pre-trained Transformer) models, are machine learning models that are trained on large amounts of text data and can generate new text that is similar to the training data. These models use techniques such as autoregression and attention mechanisms to generate coherent and meaningful text.
Text generation can be used in a variety of applications, such as chatbots, virtual assistants, and content creation. It is also used in creative applications such as poetry and fiction writing.
However, text generation can also pose ethical and social challenges, such as the potential for generating fake news and misinformation. Therefore, it is important to ensure that text generation models are trained responsibly and used in ethical ways.
Machine translation: Machine translation is an NLP task that involves automatically translating text from one language to another using a machine learning model. The goal of machine translation is to enable communication between people who speak different languages and to facilitate cross-lingual information retrieval.
Machine translation can be done using different approaches, including rule-based systems, statistical machine translation, and neural machine translation. Neural machine translation is the most popular approach for machine translation today, and it uses deep learning models to translate text.
Neural machine translation models use a sequence-to-sequence architecture that consists of an encoder network and a decoder network. The encoder network processes the input text and generates a hidden representation of the text, which is then used by the decoder network to generate the translated text.
Machine translation models are typically trained on large parallel corpora, which consist of pairs of sentences in the source language and the target language. During training, the model learns to map the source language sentences to the corresponding target language sentences.
Machine translation is used in a variety of applications, such as website translation, document translation, and real-time translation in communication tools. However, machine translation is still challenging, and the quality of machine translation can vary depending on factors such as the language pair, the domain of the text, and the quality and size of the training data. Therefore, machine translation is often used in combination with human translators to ensure accuracy and fluency in translations.
Summarization: Summarization is an NLP task that involves automatically generating a shorter version of a longer text while retaining the most important information. The goal of summarization is to help people quickly and efficiently understand the main points of a document without having to read the entire document.
There are two main types of summarization: extractive summarization and abstractive summarization.
Extractive summarization involves selecting the most important sentences or phrases from the original text and concatenating them to form a summary. This approach is based on identifying the most informative content in the original text and presenting it in a concise and coherent manner.
Abstractive summarization, on the other hand, involves generating a summary that is not limited to the original text, but instead generates new phrases and sentences to convey the main points of the text. This approach is more challenging, as it requires the model to have a deep understanding of the content and to be able to generate coherent and grammatically correct sentences.
Summarization can be done using different techniques, including rule-based methods, statistical methods, and deep learning methods such as neural networks. The most common approach for summarization today is using neural networks, particularly transformer-based models such as BERT and T5.
Summarization is used in a variety of applications, such as news summarization, document summarization, and social media summarization. It can help people quickly understand the most important information from a large volume of text and improve efficiency in information retrieval. However, summarization is still a challenging task, particularly for abstractive summarization, and further research is needed to improve the quality of summarization models.
Question answering: Question answering is an NLP task that involves automatically generating an answer to a natural language question posed by a user. The goal of question answering is to enable users to quickly and efficiently find the information they are looking for without having to manually search through a large amount of text.
Question answering can be done using different techniques, including keyword-based approaches, rule-based approaches, and machine learning approaches. The most common approach for question answering today is using deep learning models such as transformers.
Question answering models use a combination of natural language processing techniques, such as parsing and entity recognition, to understand the question and generate an answer. These models are typically trained on large datasets of question-answer pairs, such as Wikipedia or other knowledge bases.
There are two main types of question answering: open-domain question answering and closed-domain question answering. Open-domain question answering involves answering questions about any topic, while closed-domain question answering involves answering questions about a specific domain or topic.
Question answering is used in a variety of applications, such as virtual assistants, chatbots, and search engines. It can help people quickly and efficiently find the information they are looking for and improve efficiency in information retrieval. However, question answering is still a challenging task, particularly for open-domain question answering, and further research is needed to improve the quality of question answering models.
Dialogue generation: Dialogue generation is an NLP task that involves automatically generating human-like responses to a given dialogue context. The goal of dialogue generation is to enable machines to carry on a natural and coherent conversation with humans, and to support applications such as chatbots and virtual assistants.
Dialogue generation can be done using different approaches, including rule-based methods, template-based methods, and machine learning methods such as sequence-to-sequence models and transformer-based models. The most common approach for dialogue generation today is using neural network-based models, particularly transformers.
Dialogue generation models use the context of the conversation, including previous turns and user intents, to generate a response that is contextually relevant and coherent. These models are typically trained on large datasets of dialogues, such as the Cornell Movie Dialogues Corpus or the Persona-Chat dataset.
There are several challenges in dialogue generation, such as generating diverse and engaging responses, handling sarcasm and humor, and ensuring that the generated responses are contextually appropriate and consistent with user intents. To address these challenges, researchers are exploring techniques such as reinforcement learning and adversarial training.
Dialogue generation is used in a variety of applications, such as chatbots, virtual assistants, and customer support systems. It can help improve user engagement and provide a more natural and conversational user experience. However, dialogue generation is still a challenging task, and further research is needed to improve the quality of dialogue generation models.
Story generation: Story generation is an NLP task that involves automatically generating a coherent and engaging story from a given prompt or context. The goal of story generation is to enable machines to create compelling and entertaining stories that can be used for entertainment or educational purposes.
Story generation can be done using different approaches, including rule-based methods, template-based methods, and machine learning methods such as sequence-to-sequence models and transformer-based models. The most common approach for story generation today is using neural network-based models, particularly transformers.
Story generation models use the prompt or context to generate a sequence of events and characters that form a coherent and engaging narrative. These models are typically trained on large datasets of stories, such as the Creative Commons Corpus or the ROCStories dataset.
There are several challenges in story generation, such as generating diverse and interesting characters, ensuring plot coherence, and maintaining a consistent tone and style throughout the story. To address these challenges, researchers are exploring techniques such as reinforcement learning and adversarial training.
Story generation is used in a variety of applications, such as video game and movie scriptwriting, content creation for marketing purposes, and educational materials. It can help improve the quality and efficiency of content creation and provide a more personalized user experience. However, story generation is still a challenging task, and further research is needed to improve the quality of story generation models.
Language model fine-tuning: Language model fine-tuning is the process of adapting a pre-trained language model to a specific task or domain by further training it on a task-specific dataset. The goal of fine-tuning is to improve the performance of the pre-trained language model on a specific task by leveraging the knowledge and representations learned from the large pre-training corpus.
The pre-training of a language model involves training a model on a large corpus of text, such as Wikipedia or Common Crawl, to learn general language patterns and semantic representations. The resulting pre-trained model can then be fine-tuned on a smaller dataset for a specific task, such as sentiment analysis, question answering, or text classification.
Fine-tuning a pre-trained language model involves initializing the model with the pre-trained weights and then training it on the task-specific dataset using a supervised learning approach. The fine-tuning process typically involves several hyperparameters, such as learning rate, batch size, and number of training epochs, which need to be carefully tuned to achieve the best performance on the task.
Fine-tuning a pre-trained language model has several advantages over training a model from scratch. Firstly, pre-trained models have already learned general language patterns and representations that can be leveraged for the specific task. Secondly, fine-tuning requires less training data than training a model from scratch, which can be particularly useful in low-resource settings. Finally, fine-tuning can significantly reduce the training time and computational resources required for training a model from scratch.
Language model fine-tuning has become a popular technique in NLP and has been used in various applications, such as sentiment analysis, text classification, question answering, and natural language generation.
Both categories of tasks are important in NLP and often overlap, as the insights and understanding gained from NLP analysis tasks can be used to inform and improve NLP generation tasks.
Applications of Natural Language Processing (NLP)
Natural Language Processing (NLP) has many applications in various fields. Here are some of the most common applications of NLP:
Text classification: NLP is used in text classification tasks such as spam filtering, sentiment analysis, and topic modeling. These tasks are used in various industries, including social media, e-commerce, and customer support.
Machine translation: NLP is used in machine translation tasks such as translating between different languages. Machine translation is used in international business, diplomacy, and travel industries.
Named Entity Recognition (NER): NLP is used in named entity recognition tasks such as identifying the names of people, organizations, and locations in a text. NER is used in various industries, including journalism, marketing, and social media analysis.
Speech recognition: NLP is used in speech recognition tasks such as converting spoken words into text. Speech recognition is used in various industries, including voice assistants, call centers, and automated transcription services.
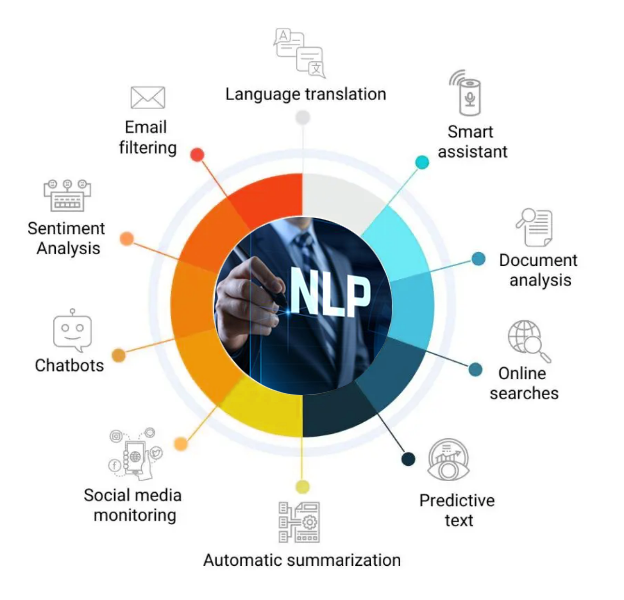
Question answering: NLP is used in question answering tasks such as chatbots and virtual assistants. These applications are used in customer support, e-commerce, and education industries.
Text summarization: NLP is used in text summarization tasks such as generating summaries of news articles, research papers, and legal documents. Text summarization is used in various industries, including journalism, research, and law.
Text generation: NLP is used in text generation tasks such as generating product descriptions, news articles, and creative writing. Text generation is used in various industries, including e-commerce, journalism, and entertainment.
Sentiment analysis: NLP is used in sentiment analysis tasks such as identifying the sentiment of a text, whether it is positive, negative, or neutral. Sentiment analysis is used in various industries, including marketing, customer support, and social media analysis.
These are just some of the many applications of NLP. As NLP technology continues to improve, we can expect to see more innovative applications in the future.
